AWS 초보를 위한 Sagemaker 사용법 (2) | Sagemaker에서 Custom Model 사용하기
in MLOps

Sagemaker에서 Custom 모델을 배포하는 방법
Sagemaker에서 Custom 모델 배포하기
Sagemaker 🩵 Docker Container
- Sagemaker 환경에서 커스텀 모델을 배포하는 법을 배우기 전, Sagemaker가 모델을 배포할 때 Docker Container를 어떤 식으로 활용하는지 이해하는게 좋습니다.
- 아래는 Sageamaker Endpoint가 도커 컨테이너를 활용하는 법을 나타낸 flowchart입니다.
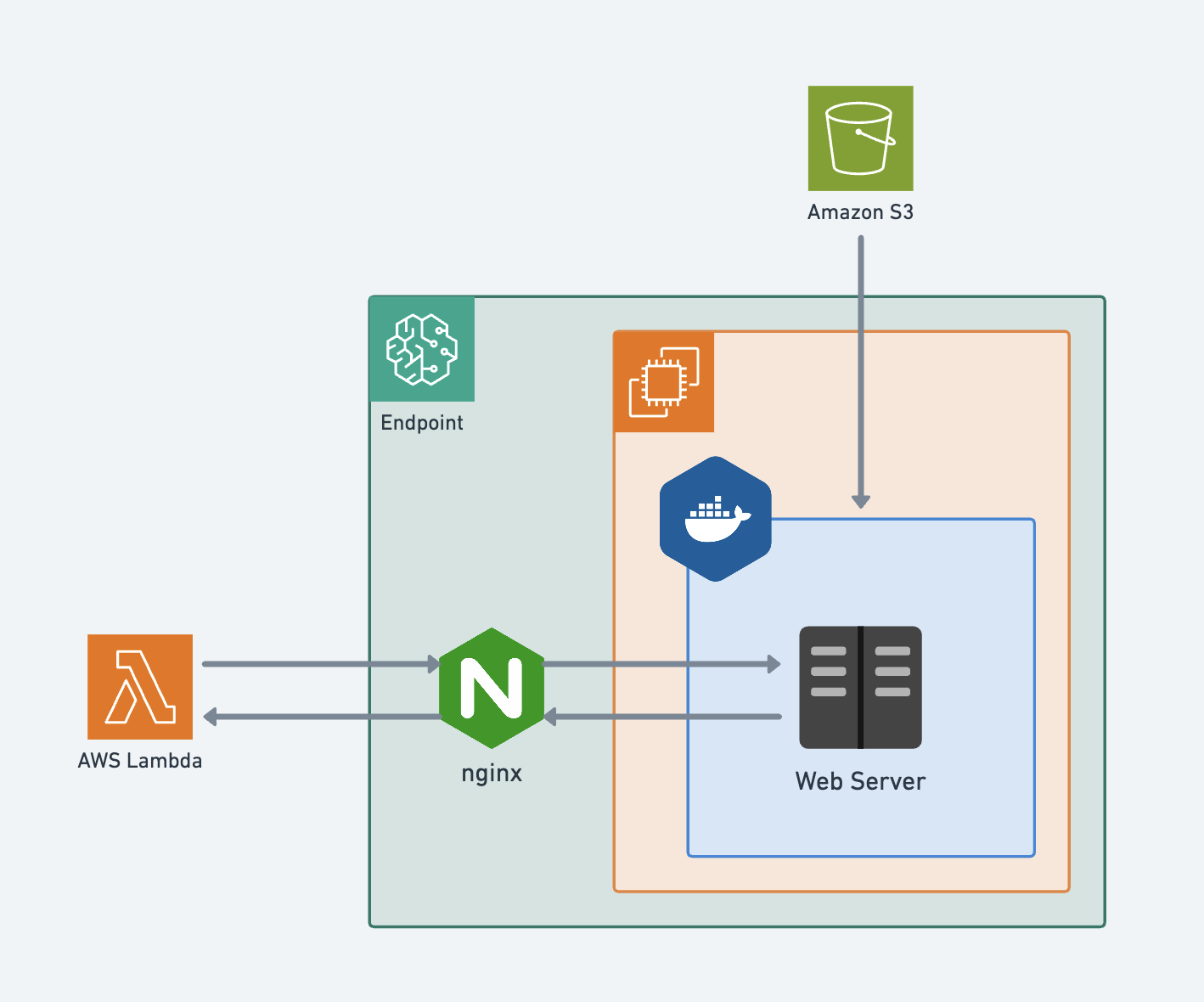
- Sagemaker Endpoint는 ECR에서 모델이 돌아갈 Docker Container를 불러옵니다.
- S3에서는 모델과 관련된 파일들을 호출합니다.
- API나 사용자가 Endpoint를 호출하면, REST API형식으로 input을 받고, 컨테이터 내에서 처리 후, 결과값을 반환합니다.
- 이번 블로그 포스팅에서는 모델을 S3에 저장하는법, 컨테이서 생성하는 방법, 그리고 최종적으로 Sagemaker Endpoint를 생성하는 방법들에 대해 포스팅 해보겠습니다.
- 아래 모든 코드들은 Sagemaker Notebook 환경에서 Jupyter Notebook로 실행하면 보다 편하게 설정할 수 있습니다.
커스텀 모델을 배포해야 하는 경우 🤷🏻♂️
- AWS Sagemaker 환경에서 작업을 하다보면, Sagemaker가 제공하는 환경만으로 모델 배포가 어려운 경우가 있습니다.
- 예를 들어, 주로 사용하는 Tensorflow, Pytorch, XGBoost와 같은 패키지 외, AWS Sagemaker 환경에서 제공하지 않는 패키지를 모델 훈련,배포 환경에서 활용하는 경우, 커스텀 Docker container를 만들어서 배포해야 하는 경우가 있습니다.
- Sagemaker에서 커스터마이징한 모델을 배포하는 방법은 다음과 같은 단계들로 진행됩니다.
- Sagemaker 모델 서빙 스크립트 작성하기
- 모델 S3에 업로드하기
- 사용자 정의 Docker 이미지를 AWS ECR에 업로드하기
- SageMaker에서 모델 생성하기
- Endpoint Configuration 생성하기
- Endpoint 생성하기
- Endpoint 호출하기
1. Sagemaker 모델 서빙 스크립트 작성하기 (inference.py)
- 먼저, Sagemaker Endpoint에서 모델과 입출력 데이터를 처리하는 python 코드를 작성해야 합니다.
inference.py는 입력 request를 전처리하고, 추론하고, 추론된 결과를 후처리하는 코드를 포함합니다.model_fn: 모델이 저장되어 있는 경로를 입력으로 받고, 모델을 재생성하고 모델과 모델 관련 정보를 반환하는 함수입니다.input_fn: 입력 데이터를 raw data로 입력받고, 데이터를 모델 입력 형식에 맞춰 반환합니다.predict_fn:input_fn에서 변환된 데이터와 모델을 입력받고, 최종 결과를 후처리한 후에 결과를 반환합니다.output_fn: 후처리된 최종 결과를 받고, json형식으로 변환한 후 최종 output 형식을 반환합니다.
inference.py는 다음과 같은 형식으로 작성될 수 있습니다. 각 함수의 내부 로직은 필요에 따라 추가로 커스텀할 수 있습니다.
# inference.py
def model_fn(model_dir):
...
return model, transform
def input_fn(request_body, request_content_type):
...
return inputs
def predict_fn(input_data, model):
...
return processed_data
def output_fn(prediction, accept):
...
return json.dumps(prediction), accept
inference.py가 잘 작동되는지 디버깅하려면, 아래고 같은 임시 코드로 결과값이 잘 반환되는지 확인합니다.
import json
from inference import model_fn, predict_fn, input_fn, output_fn
response, accept = output_fn(
predict_fn(
input_fn(payload, "text/csv"),
model_fn("./")
),
"application/json"
)
json.loads(response)
2. 모델 S3에 업로드하기
inference.py가 잘 작동되는지 확인했다면, 이제 모델을 S3에 저장해줍니다.- 모델을 올리기 전, 먼저 모델에 필요한 파일들과
inference.py를 하나의 압축파일로 압축해줍니다.- Sagemaker에선 주로
tar.gz형식으로 압축해 줍니다.
- Sagemaker에선 주로
tar -czvf ./model.tar.gz -C ./ model.joblib inference.py
- 모델을 압축한 뒤, boto3를 사용하여 모델을 S3로 업로드해줍니다.
import boto3
from datetime import datetime
bucket = "bucket_name"
object_key = f"model_function/model.tar.gz"
s3 = boto3.resource('s3')
s3.meta.client.upload_file("./model.tar.gz", bucket, object_key)
3. 사용자 정의 Docker 이미지를 AWS ECR에 업로드하기
- 훈련된 모델을 S3에 업로드 했다면, 이제 모델이 돌아갈 수 있는 환경 설정을 해 줄 차례입니다.
- 먼저, sagemaker 환경에서 AWS ECR registry에 로그인 합니다
# 도커를 Amazon ECR 레지스트리에 인증하기
aws ecr get-login-password --region $REGION | docker login --username AWS --password-stdin <docker_registry_url>.dkr.ecr.$REGION.amazonaws.com
# Amazon ECR 레지스트리에 로그인하기
aws ecr get-login-password --region $REGION | docker login --username AWS --password-stdin $ACCOUNT.dkr.ecr.$REGION.amazonaws.com
- ECR에 로그인한 후, ECR에 push할 컨테이너를 생성할 Dockerfile을 작성해줍니다. 프로젝트에 따라 AWS에서 제공하는 레지스트리에 있는 이미지를 베이스로 사용하여 필요한 환경 설정을 할 수 있습니다.
- AWS Seoul Region에서 제공하는 이미지 URL은 아래 링크에서 검색할 수 있습니다. <\br>
# Base image
FROM <docker_registry_url>.dkr.ecr.<my_aws_region>.amazonaws.com/pytorch-inference:2.0.0-gpu-py310
# 추가로 필요한 패키지 설치 / 환경 설정
RUN pip install workalendar
...
- Dockerfile 작성이 완료되면 build 커맨드로 Docker Image를 빌드해줍니다.
docker build -t model-project .
- Build가 완료된 후, ECR에 레포지토리를 생성 후, 이미지를 push 생성된 레포지토리에 push해줍니다.
# AWS ECR repository 생성
aws ecr create-repository --repository-name model-project
docker tag model-project:latest $ACCOUNT.dkr.ecr.$REGION.amazonaws.com/model-project:latest
# 태그된 이미지 레포지토리에 push
docker push $ACCOUNT.dkr.ecr.$REGION.amazonaws.com/model-project:latest
- 여기까지 완료됬으면, 배포에 필요한 모델, 그리고 도커를 사용한 환경 설정이 모두 완료됬습니다.
- 이제 생성된 모델과 컨테이너를 Sagemaker에 배포해봅시다.
4. SageMaker에서 모델 생성하기
- 먼저 Sagemaker Model Registry에 모델을 등록해야 합니다.
- 모델 등록은 다음과 같읕 python 코드로 진행할 수 있습니다.
- 이때, 모델이 저장된 s3 uri와 도커 컨테이너가 저장된 ECR url를 사용합니다.
import boto3
import sagemaker
sagemaker_client = boto3.client(service_name="sagemaker")
role = sagemaker.get_execution_role()
bucket = "bucket_name"
object_key = f"model_function/model.tar.gz"
model_name = f"model-test"
primary_container = {
"Image": f"{my_aws_account}.dkr.ecr.{my_aws_region}.amazonaws.com/model-project:latest",
"ModelDataUrl": f"s3://{bucket}/{object_key}"
}
create_model_response = sagemaker_client.create_model(
ModelName=model_name,
ExecutionRoleArn=role,
PrimaryContainer=primary_container)
5. 엔드포인트 구성 (Endpoint Configuration) 생성하기
- 모델 등록이 완료되었다면, 등록된 모델로 endpoint Configuration을 생성합니다.
- Endpoint Configuration은 모델, 컨테이너가 돌아가는 환경을 설정하는 구성입니다.
endpoint_config_name = f"ai-vad-model-config"
sagemaker_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[{
"InstanceType": "ml.g5.xlarge",
"InitialVariantWeight": 1,
"InitialInstanceCount": 1,
"ModelName": model_name,
"VariantName": "AllTraffic"}])
6. 엔드포인트 생성하기
- 마지막으로 사용자나 API등이 직접적으로 호출할 수 있는 Sagemaker Endpoint를 생성합니다.
endpoint_name = f"ai-vad-model-endpoint-{current_datetime}"
sagemaker_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name)
- Endpoint는 생성되기 까지 좀 오래 걸릴 수 있습니다. 아래 코드로 Endpoint 생성 상태를 확인할 수 있습니다. 생성 상태가
InService면 모델 Endpoint가 성공적으로 생성된 걸 확인할 수 있습니다.
response = sagemaker_client.describe_endpoint(EndpointName=endpoint_name)
print(response["EndpointStatus"])
7. 엔드포인트 호출하기
- Sagemaker Endpoint가 성공적으로 생성되면, 커스텀 모델이 최종적으로 배포된 것입니다. 생성된 Endpoint를 테스트하려면, 아래 코드로 Endpoint 호출을 테스트할 수 있습니다.
payload = "1.0,2.0,3.2,2.2,1.23,11.5"
sagemaker_runtime = boto3.client("runtime.sagemaker")
response = sagemaker_runtime.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="text/csv",
Body=payload
)
response = json.loads(response["Body"].read().decode())
