시계열 데이터 패키지 - Darts

Darts로 손쉽게 시계열 예측하기
시계열 데이터는 많은 분야에서 중요한 역할을 하고 있습니다. 금융, 기상, 생산, 건강 등 여러 영역에서 시계열 데이터를 분석하고 예측하는 것은 중요한 의사 결정을 내리는 데 도움이 됩니다. 그리고 이러한 작업을 수행하기 위해 파이썬에서는 다양한 라이브러리가 제공되고 있습니다.
그 중 한 가지가 바로 Darts입니다. Darts는 “다양한 시계열 모델링과 예측을 위한 라이브러리”라는 이름에서 알 수 있듯이, 파이썬에서 시계열 데이터를 다루고 예측하기 위한 강력한 도구입니다. 스위스의 회사 Unit8에서 개발된 이 라이브러리는 사용하기 쉽고, 다양한 모델을 지원하여 다양한 시계열 데이터에 대해 유연하게 대응할 수 있습니다.
Darts의 주요 기능
Darts는 시계열과 관련해서 여러 기능들을 제공합니다. 아래 그림은 Darts에서 제공하는 여러 시계열 관련 기능들을 그룹화하여 표시한 도표입니다.
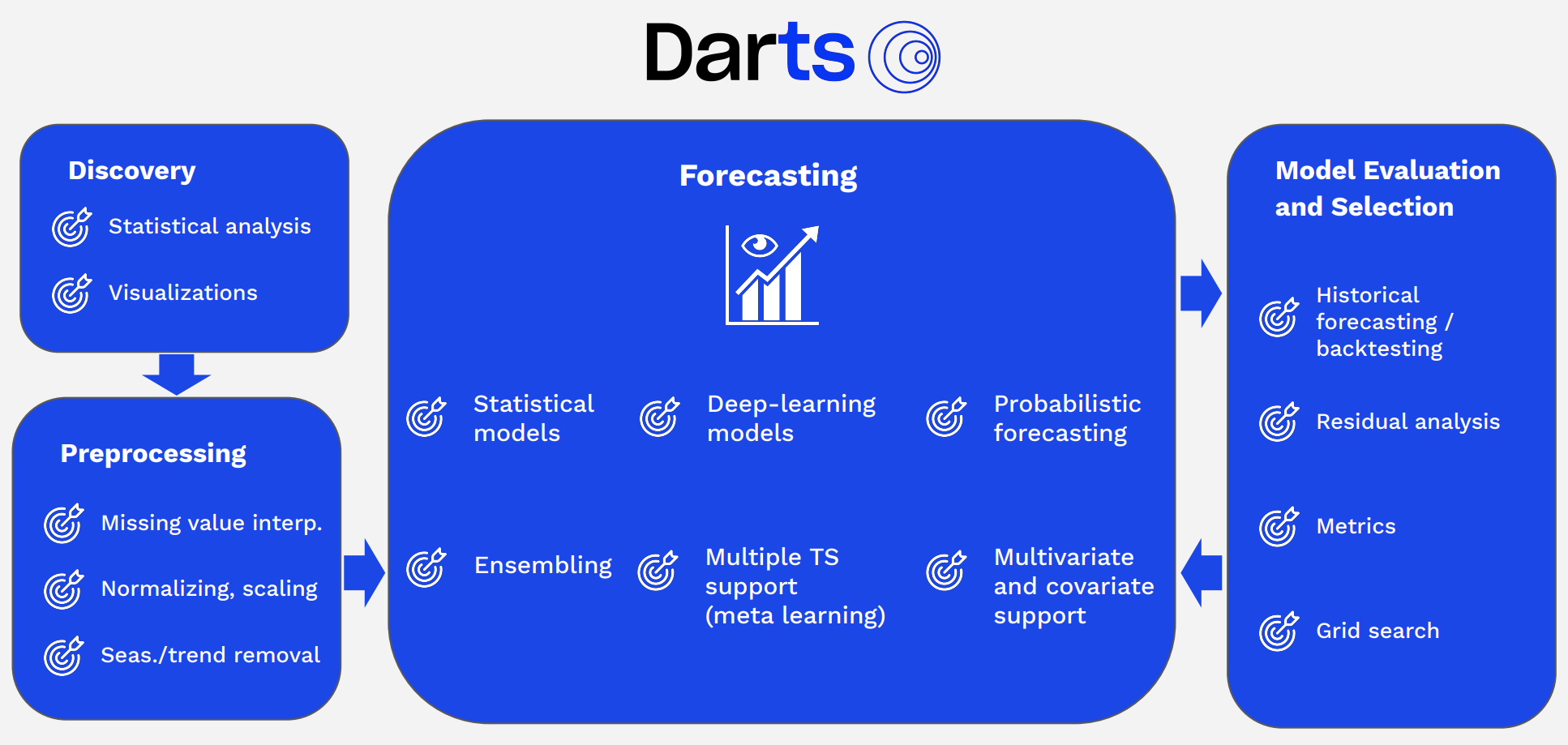
시계열 모델링: Darts는 ARIMA, Prophet, RNN, LSTM, TCN 등 다양한 시계열 모델을 제공합니다. 이를 통해 사용자는 자신의 데이터에 가장 적합한 모델을 선택할 수 있습니다.
시계열 예측: Darts를 사용하면 시계열 데이터의 미래 값을 예측할 수 있습니다. 이때 예측의 불확실성을 고려하여 신뢰 구간도 함께 제공됩니다.
시계열 데이터 전처리: Darts는 데이터를 전처리하고 변환하는 다양한 기능을 제공하여 모델링하기 전에 데이터를 준비할 수 있습니다. 이는 데이터의 정규화, 결측치 처리, 이상치 탐지 등을 포함합니다.
시계열 분해: Darts는 시계열 데이터를 추세, 계절성, 잔차로 분해하여 각 구성 요소의 패턴을 분석할 수 있습니다. 이를 통해 데이터의 특성을 더 잘 이해하고 예측 모델을 개선할 수 있습니다.
검증 및 평가: Darts는 모델의 성능을 평가하고 검증하기 위한 다양한 도구를 제공합니다. 이를 통해 모델의 예측 능력을 확인하고 개선할 수 있습니다.
이번 포스팅에서는 Darts를 사용하여 손쉽게 시계열 데이터를 시각화/전처리하고, 여러 모델들을 실험해 볼 수 있는 Pipeline을 만드는 방법에 대해 알아보겠습니다.
Darts로 시계열 데이터 시각화/전처리하기
Data
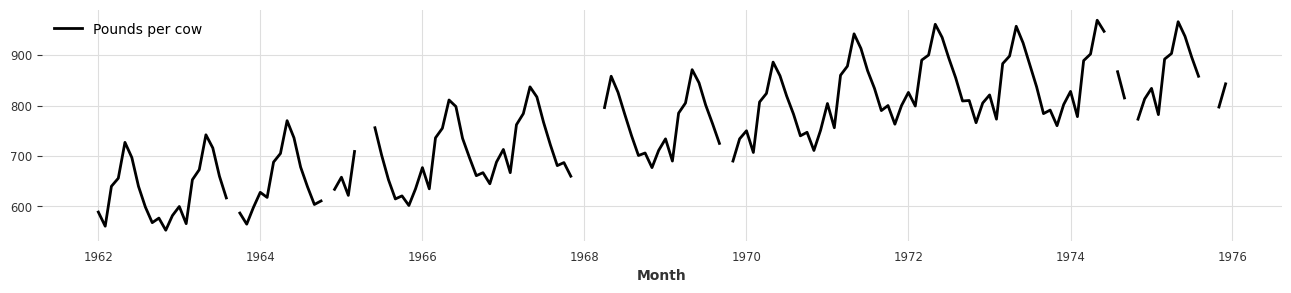
- 먼저, Dart에서 기본적으로 제공하는 예시 시계열 데이터들 중 하나를 사용하여 예시를 진행해 보겠습니다.
- 이번 포스팅에서는 월별 우유 판매 데이터셋을 사용하겠습니다 (
MonthlyMilkIncompleteDataset). - Darts에서는 모든 시계열 데이터를
TimeSeries클래스로 변환하여 다룹니다.
from darts.datasets import MonthlyMilkIncompleteDataset
import matplotlib.pyplot as plt
series = MonthlyMilkIncompleteDataset().load()
plt.figure(figsize=(16, 3))
series.plot();
Scaler
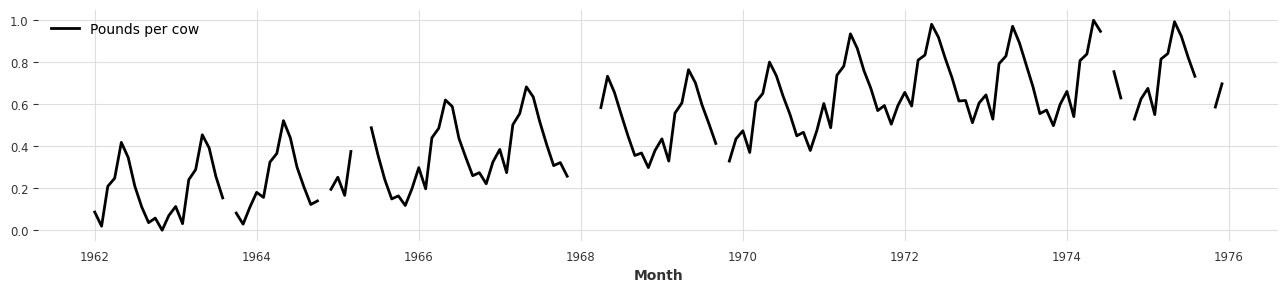
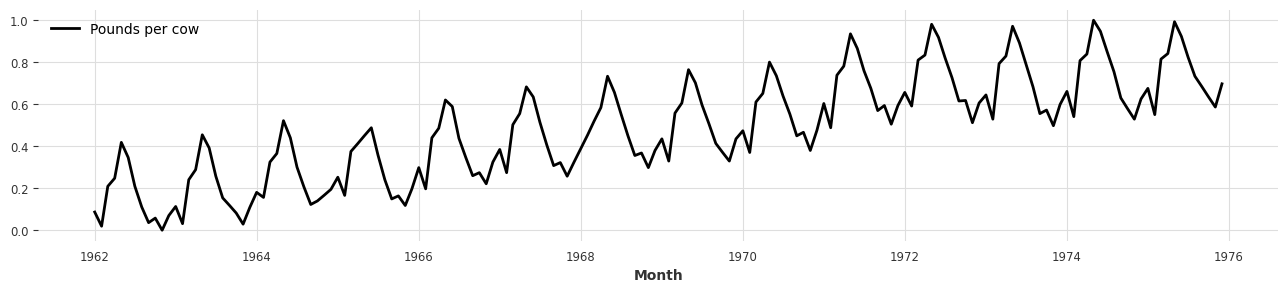
- Darts에서 제공하는 Scaler 클래스를 사용하여 시계열 데이터셋을 간단히 스케일을 할 수 있습니다.
- 기본으로 제공하는 Scaler는 MinMaxScaler이며, 원하는 방식의 스케일링 전처리르 사용할 수 있습니다 (ex. StandardScaler, …)
- scikit-learn의 API와 비슷하게 작동하며,
fit으로 Sclar를 fit하고,transform으로 실제 시계열 데이터를 변환합니다. inverse_transform을 사용하면, 스케일된 데이터를 원본으로 복구할 수도 있습니다.
from darts.dataprocessing.transformers import Scaler
scaler = Scaler()
rescaled = scaler.fit_transform(series)
plt.figure(figsize=(16, 3))
rescaled.plot();
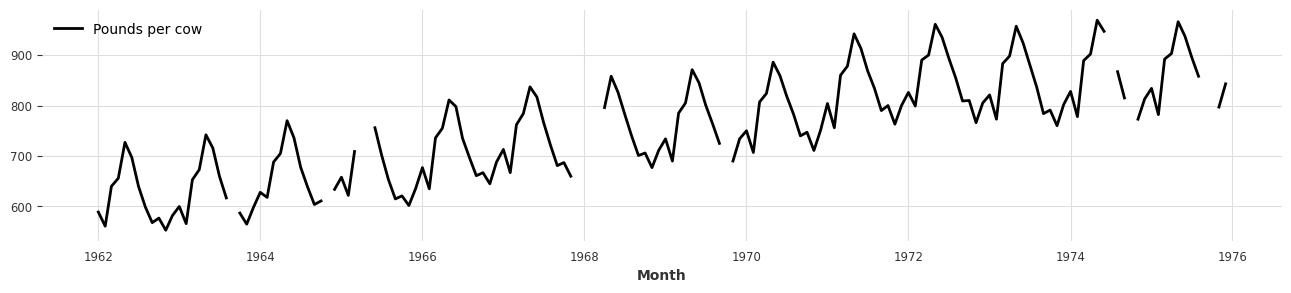
back = scaler.inverse_transform(rescaled)
plt.figure(figsize=(16, 3))
back.plot();
MissingValuesFiller
- 시계열 데이터를 다루다 보면, 중간중간에 missing values들이 많을 때가 많습니다.
- 이런 빠진 데이터들을 MissingValuesFiller 클래스로 여러 방식으로 interpolate 할 수 있습니다.
from darts.dataprocessing.transformers import MissingValuesFiller # type: ignore
series_missing = series.copy()
plt.figure(figsize=(16, 3))
series_missing.plot();
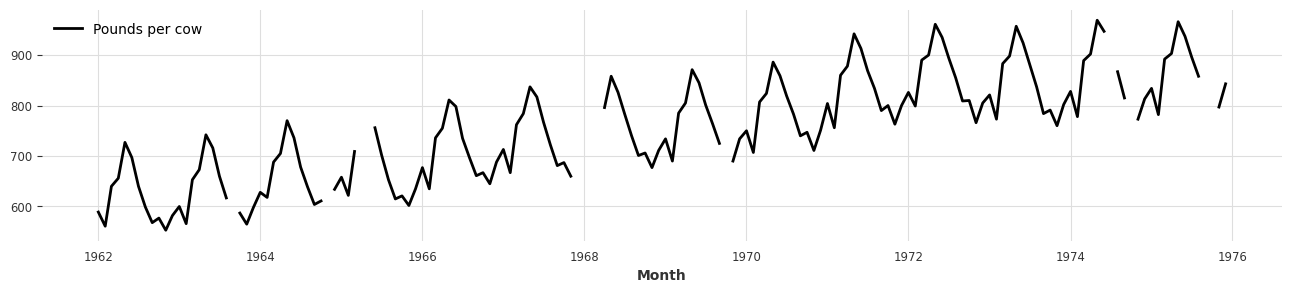
filler = MissingValuesFiller()
filled_linear = filler.transform(series_missing, method="linear")
filled_quadratic = filler.transform(series_missing, method="quadratic")
plt.figure(figsize=(16, 3))
filled_linear.plot(label='filled_linear')
filled_quadratic.plot(label='filled_quadratic')
series_missing.plot(label='original');
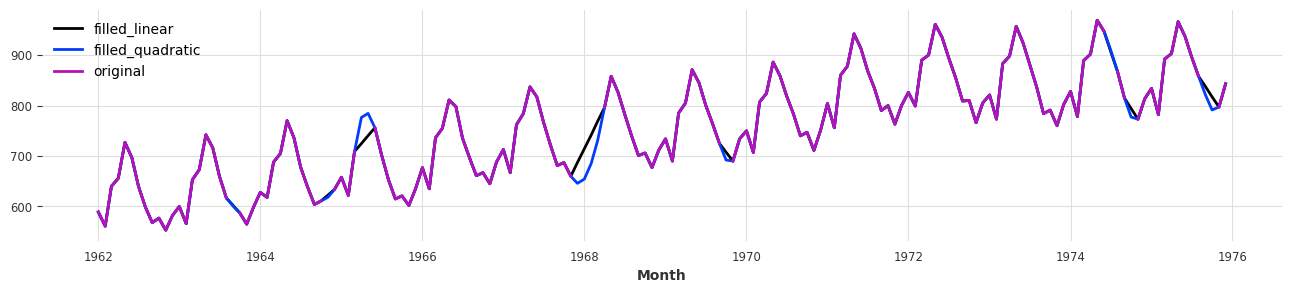
Pipeline
- 시계열 데이터를 전처리 하다보면 수많은 전처리 방식을 사용할 경우가 많습니다.
- 사용하는 전처리 방식이 많아질 수록 전처리와 관련된 class/변수들을 관리하기도 어려워 지고, 같은 전처리 환경으로 배포하는 과정에도 많은 어려움이 생길 수 있습니다.
- 이를 더 편리하게 만들어주기 위해, darts는 scikit-learn과 같이 데이터
Pipeline기능을 제공해 줍니다.
from darts.dataprocessing import Pipeline
incomplete_series = series.copy()
# 데이터 전처리에 필요한 class 선언하기
filler = MissingValuesFiller()
scaler = Scaler()
# Pipeline 만들기
pipeline = Pipeline([filler, scaler])
transformed = pipeline.fit_transform(incomplete_series)
plt.figure(figsize=(16, 3))
transformed.plot();
- Pipeline 내부의 모든 기능들에서 inverse_transform이 가능하면, Pipeline 자체에서도 inverse_transform이 가능합니다.
- 만약 Pipeline 내부 구성 중 inverse_transform이 불가능한 기능이 섞여 있으면 (ex.
MissingValueFiller),partial=True로 설정하여 그 기능을 제외하고 inverse_transform이 가능하도록 설정할 수도 있습니다.
back = pipeline.inverse_transform(transformed, partial=True)
plt.figure(figsize=(16, 3))
back.plot();
- 다음 단계로 넘어가기 전, darts 딥러닝 모델들은 float32 데이터타입으로 다뤄야 해서, 변환된 데이터를
np.float32로 변환시켜줍니다.
import numpy as np
transformed = transformed.astype(np.float32)
전처리된 데이터로 모델 훈련하기
- 훈련할 데이터가 모두 준비되면, 이제 모델을 설정할 차례입니다.
- Darts에서는 간단한 통계모델부터 복잡한 딥러닝 모델까지 다양한 모델들을 제공합니다. (from ARIMA to Pytorch Forcast)
- 이 링크에서 Darts에서 제공하는 모든 모델들을 확인할 수 있습니다
Darts 모델 훈련 과정
- Darts에서 모델이 훈련될 때 다음과 같은 과정을 거칩니다.
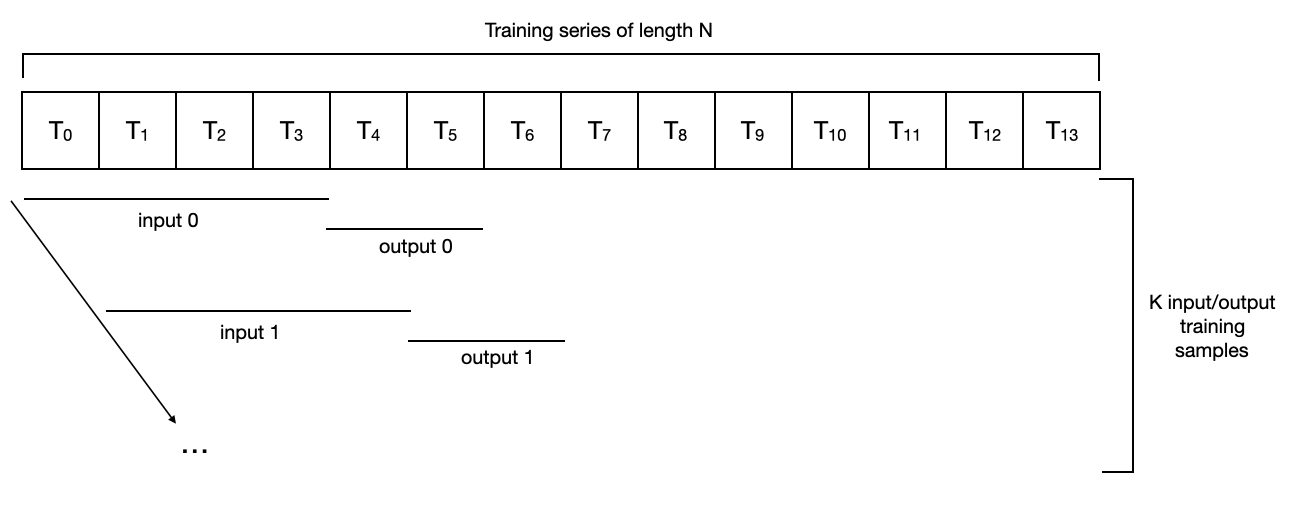
- 입력 데이터: 데이터 첫 부분부터 설정한 데이터 크기(
input_chunk_length)만큼 input 데이터를 자르고, 한 칸씩 옮기며 같은 크기로 계속 자릅니다. (T0 ~ T3 / T1~T4 / …) 출력 데이터: 입력 데이터 바로 뒷단계 부터
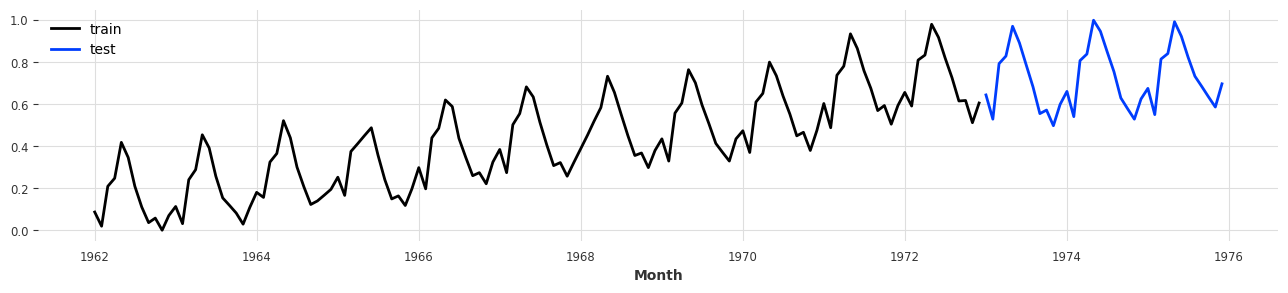
output_chunk_length만큼 데이터를 자르고, 입력 데이터와 같은 방식으로 옮기면서 계속 자릅니다. (T4~T5 / T5~T6 / …)- 모델 입력 예시를 들기 위해 위에서 처리한 데이터를 train/test split 해주겠습니다.
train, test = transformed[:-36], transformed[-36:]
plt.figure(figsize=(16, 3))
train.plot(label='train')
test.plot(label='test');
Covariates
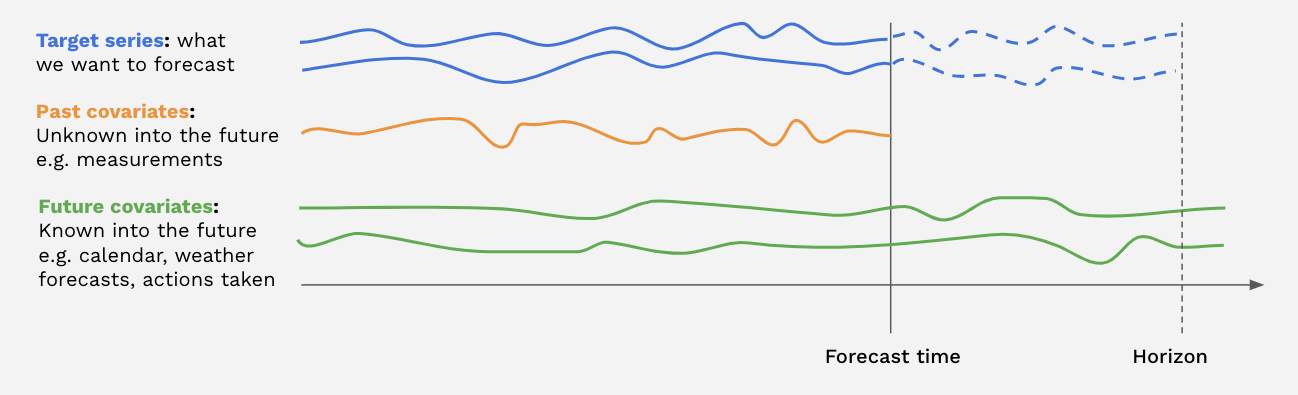
- 모델에게 훈련 데이터를 제공할 때 우리가 사용하고 싶은 원본 데이터 외, 데이터와 관련된 시계열 데이터를 한번에 제공해 줄 수도 있습니다. 이런 target데이터 외 다른 데이터들을 darts에선
covariates라고 부릅니다. - Covariates에는 크게 세 종류가 있습니다.
- Past Covariates: 예측 시점에서 이미 알려진 시계열의 과거 값을 나타냅니다. 일반적으로 측정하거나 관찰해야 할 것들입니다.
- Future Covariates: 예측 시점에서 이미 예측 기간 동안의 미래 값이 알려진 시계열을 나타냅니다. 이는 알려진 미래의 휴일이나 날씨 예보와 같은 것을 나타낼 수 있습니다.
- Static Covariates: 시간이 변해도 유지되는 값들 ex) 건물 전열 사용량 데이터의 건물 종류
모델의 종류에 따라 Past Covaiates만 사용하는 모델도 있고, Future Covariates만 사용하는 모델도 있고, 모두 사용하는 모델들도 있습니다. 어떤 모델을 사용하냐에 따라 제공하는 Covariates를 다르게 해줘야 합니다. 포스팅의 길이를 위해 이번 포스팅에서는 Past Covariates와 Future Covariates만 살펴보겠습니다.
모델에게 Covariates를 제공해 주는 방법은 크게 두 가지 방법이 있습니다
모델 외부에서 Covariates 제작하는 방법
- 모델에 데이터를 입력하기 전, covariates를 먼저 생성 후 모델에 target 데이터와 함께 넣어줄 수 있습니다.
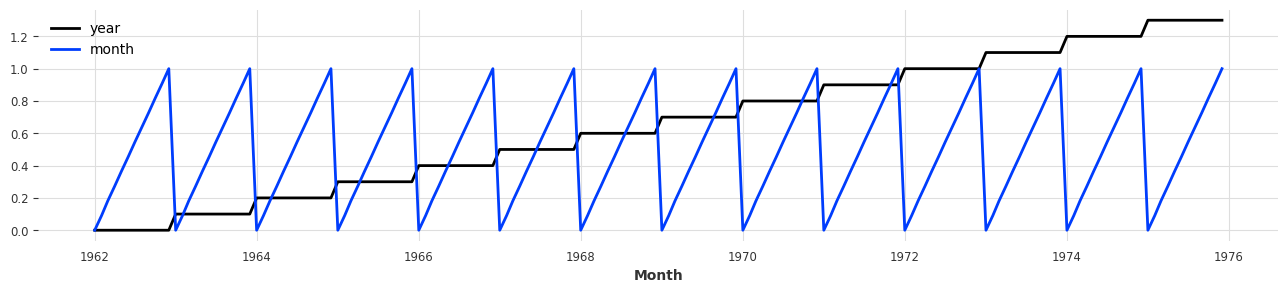
- 이번 예시에서는 각 데이터의 월와 연도 데이터를 past covariates와 future covariates로 만들어보겠습니다.
from darts.utils.timeseries_generation import datetime_attribute_timeseries
from darts import concatenate
# transformed 데이터에서 연도, 월 데이터 추출
milk_year = datetime_attribute_timeseries(transformed, attribute='year')
milk_month = datetime_attribute_timeseries(transformed, attribute='month')
# 연도, 월 데이터 병합 (stack)
milk_covariates = milk_year.stack(milk_month)
# covariates를 train/test 데이터로 나누기
milk_train_covariates, milk_val_covariates = milk_covariates[:-36], milk_covariates[-36:]
# MinMaxScaler로 데이터 스케일링 하기
scaler_covariates = Scaler()
milk_train_covariates = scaler_covariates.fit_transform(milk_train_covariates)
milk_val_covariates = scaler_covariates.transform(milk_val_covariates)
# Train/test 데이터 다시 concatenate 하고 데이터 타입 변환하기
milk_covariates = concatenate([milk_train_covariates, milk_val_covariates])
milk_covariates = milk_covariates.astype(np.float32)
plt.figure(figsize=(16, 3))
milk_covariates.plot();
- Covariates들을 설정한 후, 모델을 fit할 때 아래와 같이 covariates들을 설정해 줄 수 있습니다.
from darts.models import TiDEModel
model = TiDEModel(
input_chunk_length=10,
output_chunk_length=10,
)
model.fit(
series=train,
past_covariates=milk_covariates,
future_covariates=milk_covariates,
)
number of `past_covariates` features is <= `temporal_width_past`, leading to feature expansion.number of covariates: 2, `temporal_width_past=4`.
number of `future_covariates` features is <= `temporal_width_future`, leading to feature expansion.number of covariates: 2, `temporal_width_future=4`.
GPU available: True (mps), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
| Name | Type | Params
-----------------------------------------------------------
0 | criterion | MSELoss | 0
1 | train_metrics | MetricCollection | 0
2 | val_metrics | MetricCollection | 0
3 | past_cov_projection | _ResidualBlock | 912
4 | future_cov_projection | _ResidualBlock | 912
5 | encoders | Sequential | 50.0 K
6 | decoders | Sequential | 57.8 K
7 | temporal_decoder | _ResidualBlock | 726
8 | lookback_skip | Linear | 110
-----------------------------------------------------------
110 K Trainable params
0 Non-trainable params
110 K Total params
0.442 Total estimated model params size (MB)
Training: | | 0/? [00:00<?, ?it/s]
`Trainer.fit` stopped: `max_epochs=100` reached.
TiDEModel(output_chunk_shift=0, num_encoder_layers=1, num_decoder_layers=1, decoder_output_dim=16, hidden_size=128, temporal_width_past=4, temporal_width_future=4, temporal_decoder_hidden=32, use_layer_norm=False, dropout=0.1, use_static_covariates=True, input_chunk_length=10, output_chunk_length=10)
모델 인자(parameter)로 covariates 설정하는 방법
- Darts에서 모델을 생성 할 때 임의로 관련 covariates들을 선언하지 않고 인자만으로 past/future covariates들을 생성할 수 있습니다.
- 모댈을 생성할 때
add_encoders인자를 추가해주면, 모델이 훈련될 때 자동으로 설정한 covariates들이 추가가 됩니다.
add_encoders = {
'cyclic': datetime 변수들의 sin/cos 인코딩 데이터를 past/future covariates로 추가합니다.
'datetime_attributes': datetime 변수 원본 데이터를 past/future covariates로 추가합니다.
'custom': 사용자가 임의로 선언한 함수를 사용하여 covariates들을 추가합니다.
'transformer': 추가된 covariates 변수들을 스케일링할 때 사용될 함수를 받습니다.
}
- 아래는
add_encoders인자가 모델을 선언할 때 어떤 식으로 사용되는지 보여줍니다.
from darts.models import TiDEModel
model = TiDEModel(
input_chunk_length=12,
output_chunk_length=12,
n_epochs=100,
random_state=0,
use_reversible_instance_norm=True,
add_encoders={
'cyclic': {
'past': ['month'] # "월(month)"데이터를 sin/cos encoding하여 past covariates로 넣습니다
},
'datetime_attribute': {
'future': ['month', 'year'] # "월(month)/연도(year)"데이터를 future covariates로 넣습니다
},
'transformer': Scaler()
}
)
model.fit(train)
number of `past_covariates` features is <= `temporal_width_past`, leading to feature expansion.number of covariates: 2, `temporal_width_past=4`.
number of `future_covariates` features is <= `temporal_width_future`, leading to feature expansion.number of covariates: 2, `temporal_width_future=4`.
GPU available: True (mps), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
| Name | Type | Params
-----------------------------------------------------------
0 | criterion | MSELoss | 0
1 | train_metrics | MetricCollection | 0
2 | val_metrics | MetricCollection | 0
3 | rin | RINorm | 2
4 | past_cov_projection | _ResidualBlock | 912
5 | future_cov_projection | _ResidualBlock | 912
6 | encoders | Sequential | 56.7 K
7 | decoders | Sequential | 66.0 K
8 | temporal_decoder | _ResidualBlock | 726
9 | lookback_skip | Linear | 156
-----------------------------------------------------------
125 K Trainable params
0 Non-trainable params
125 K Total params
0.502 Total estimated model params size (MB)
Training: | | 0/? [00:00<?, ?it/s]
`Trainer.fit` stopped: `max_epochs=100` reached.
TiDEModel(output_chunk_shift=0, num_encoder_layers=1, num_decoder_layers=1, decoder_output_dim=16, hidden_size=128, temporal_width_past=4, temporal_width_future=4, temporal_decoder_hidden=32, use_layer_norm=False, dropout=0.1, use_static_covariates=True, input_chunk_length=12, output_chunk_length=12, n_epochs=100, random_state=0, use_reversible_instance_norm=True, add_encoders={'cyclic': {'past': ['month']}, 'datetime_attribute': {'future': ['month', 'year']}, 'transformer': Scaler})
model.past_covariates_series,model.past_covariates_series로 past_covariates와 future_covariates들이 자동으로 추가되고 scale까지 진행된 것을 확인할 수 있습니다.
plt.figure(figsize=(16, 3))
model.past_covariate_series.plot();
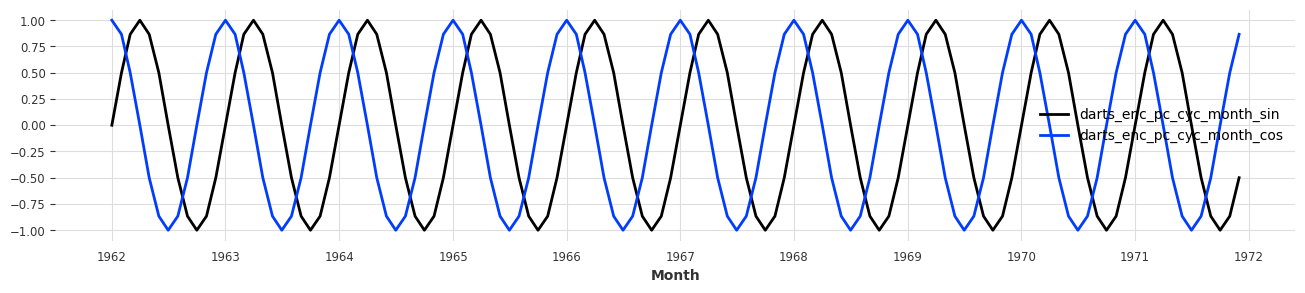
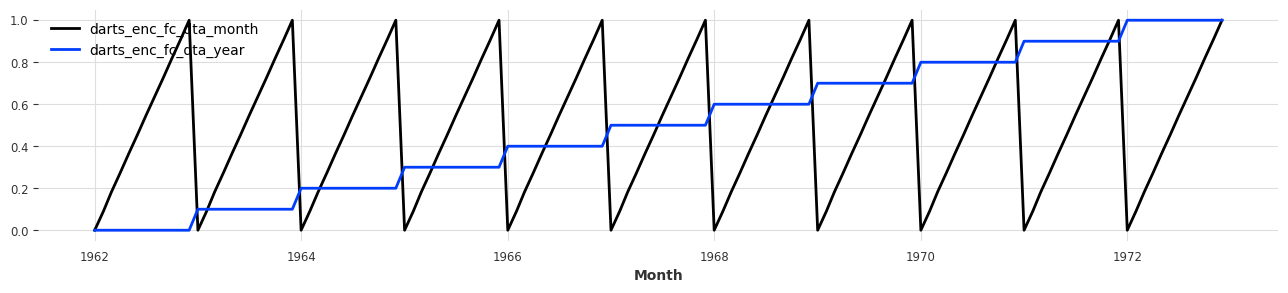
plt.figure(figsize=(16, 3))
model.future_covariate_series.plot()
<Axes: xlabel='Month'>
훈련된 모델로 예측하기
- 모델 훈련이 완료되면,
predict()를 사용하여 모델로 예측을 할 수 있습니다. - predict의 기본 인자 중 하나인
n은 몇 스텝 후를 예측할 지를 나타내는 인자입니다.n이 모델의output_chunk_length보다 짧거나 같으면, 모델 inference는 한 번만 실행되며, 결과는n길이에 맞게 잘라집니다 - 만약
n이output_chunk_length보다 길면 모델을 여러 번 호출하여n을 예측해야 합니다. 각 호출은 output_chunk_length 예측 지점을 출력합니다.n개의 최종 예측 지점에 도달할 때까지 필요한만큼 자기 회귀적으로 호출을 진행합니다.- 아래 그림과 같이 모델이 처음 호출된 후, 예측된 데이터가 원본 데이터와 함께 다시 다음 모델 호출의 입력값으로 사용됩니다.
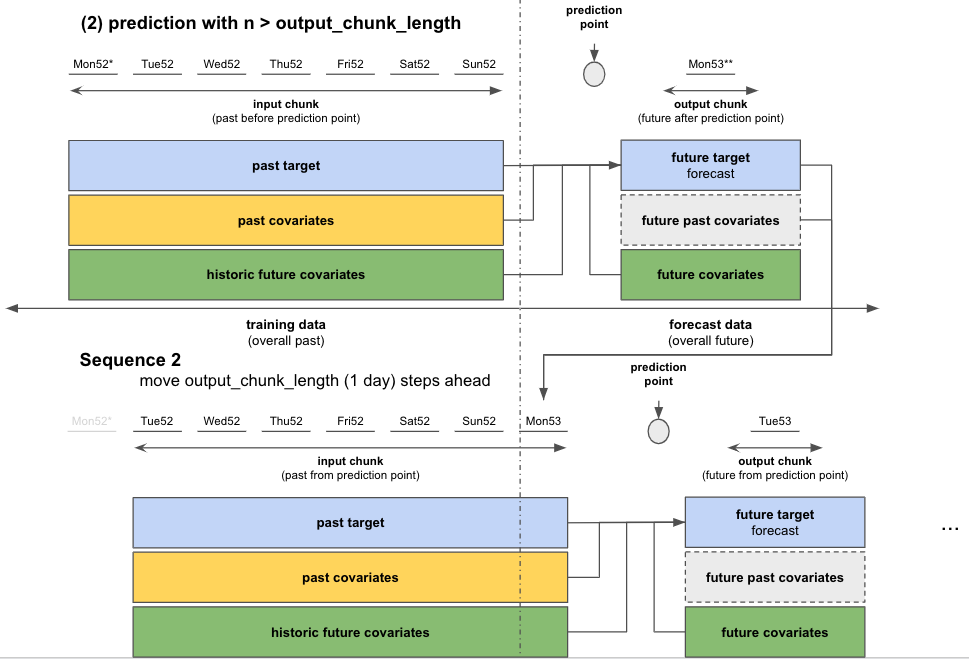
pred_less_n = model.predict(n=11)
pred_more_n = model.predict(n=24)
GPU available: True (mps), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Predicting: | | 0/? [00:00<?, ?it/s]
`predict()` was called with `n > output_chunk_length`: using auto-regression to forecast the values after `output_chunk_length` points. The model will access `(n - output_chunk_length)` future values of your `past_covariates` (relative to the first predicted time step). To hide this warning, set `show_warnings=False`.
GPU available: True (mps), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Predicting: | | 0/? [00:00<?, ?it/s]
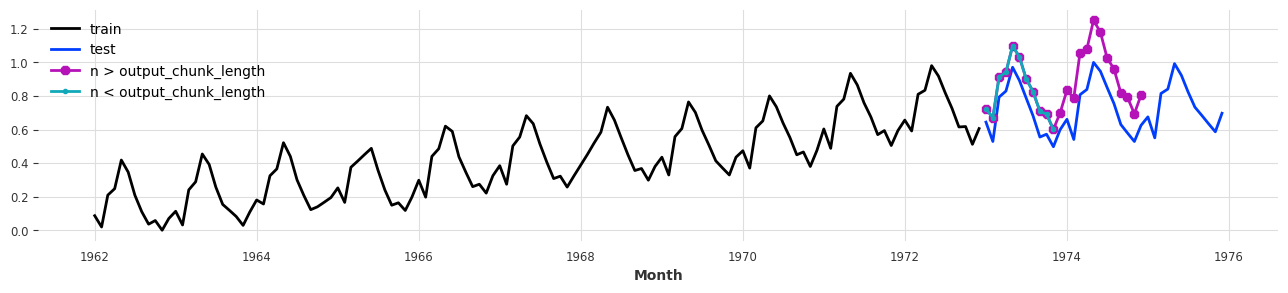
plt.figure(figsize=(16, 3))
train.plot(label='train')
test.plot(label='test')
pred_more_n.plot(label='n > output_chunk_length', marker='8')
pred_less_n.plot(label='n < output_chunk_length', marker='.');
마치며
- 이렇게 복잡한 코드 작성 없이 시계열 데이터 전처리 하는 방법과 손쉽게 딥러닝 모델들을 다룰 수 있는 Darts 패키지에 대해 알아봤습니다.
- 다음 포스팅에서는 Optuna, Hydra 등과 같은 패키지들과 함께 사용하며 시계열 딥러닝 모델 실험들을 관리할 수 있는 간단한 MLOps 환경을 구축하는 방법을 알아보겠습니다.
