에이전트 개발할 때 고려해야 할 점

현업에서 LLM 에이전트를 만들다 보면 분기 로직 설계, 데이터베이스 연동, 그리고 관측 가능성(Observability)까지 생각보다 놓치기 쉬운 요소들이 많습니다. 이 글은 최근 프로젝트 경험을 바탕으로 DSPy를 활용한 분기 노드 개발, MCP Toolbox for Databases를 이용한 DB 연동 간소화, 그리고 Langfuse를 중심으로 한 Observability 구축까지 실제로 도움이 되었던 실무 팁을 정리했습니다. 각 섹션은 바로 적용할 수 있는 방법 중심으로 정리했으니, 팀의 에이전트 품질과 배포 속도를 함께 끌어올리는 데 참고하시면 좋겠습니다.
DSPy로 LangGraph 분기 노드 개발

ChatGPT를 사용한 이미지 생성
LangGraph로 에이전트 개발을 할 때, 분기 처리 엣지 (Conditional Edge)를 사용하여 플로우를 처리하는 경우가 많습니다. 예를 들어 챗봇에서 사용자의 질문이 주제와 관련 있는 질문인지, 아닌지 판단할 때와 같은 경우죠. 이때 보통 아래와 같은 LangGraph 노드 코드와 프로세스로 분기 처리를 진행하는데요,
- 분류 프롬프트를 작성한다
- LLM + 작성된 프롬프트로 사용자 입력을 분류한다.
- 결과를 확인하면서, 프롬프트를 수동으로 수정한다.
def classification_node(state: LangGraphState) -> dict:
message = state.messages[-1] # 가장 최근 메시지 불러오기
classification_prompt = f"""
당신은 질문 분류기입니다. 사용자의 질문을 읽고, 질문이 주제와 관련 있는지 판단하고, 결과와 confidence score를 아래 JSON 형식으로 반환해주세요
{
"label": "positive" | "negative",
"score": 0.44
}
아래는 몇 가지 예시입니다.
"오늘 날씨 어때?" -> "negative"
"이번달 MAU 조회해줘" -> "positive"
"""
# Initialize the classifier pipeline
llm = ChatOpenAI(model="gpt-4o-mini")
chain = llm | JsonOutputParser()
# Run classification
result = chain.invoke(message)
# Return structured result
return {
"label": result["label"],
"score": round(result["score"], 2)
}
처음 프로토타이핑 단계에서는 이렇게 실험을 해도 괜찮았지만, 좀 더 정확도 높고 유지보수 가능한 버전을 만들어 보려 하니 프로세스가 많이 비효율적이라 느껴졌습니다.
이렇게 노드를 개발하게 되면, 예상 질문을 하나하나 테스트하면서 노드 정확도를 판단해야 하기 때문에 디버깅 프로세스가 오래 걸리고, 실제 배포했을 때의 정확도를 보장할 수 없게 됩니다.
그래서 이 문제를 해결하기 위해 좀 더 체계적인 프롬프트 엔지니어링 기법을 찾다가 DSPy라는 파이썬 패키지를 발견했습니다. (DSPy에 대한 자세한 정보는 제가 작성한 DSPy 포스팅과 DSPy 공식 문서를 참조하세요.)
DSPy는 guess-work 프롬프팅 기법에서 벗어나 데이터 기반으로 체계적으로 프롬프팅을 설계할 수 있도록 도와줍니다. 또한, DSPy는 MLFlow로 실험 트래킹도 지원하여, 프롬프트 최적화 프로세스를 투명하게 파악할 수 있습니다. DSPy를 발견한 이후 LangGraph에서 이런 분기 노드를 개발할 때, 기존 프롬프팅 엔지니어링 기법에서 벗어나 다음과 같은 프로세스를 사용했습니다
- 예상 질문 (또는 input)을 5-10개 정도 작성하거나 과거 실험 로그 기록에서 예상 질문을 추출한다.
- ChatGPT로 원하는 만큼 추가 질문 데이터 생성 (40~60개 정도)
- 각 질문마다 라벨 적용
- 프롬프트 최적화 train dataset과 test dataset 분류
- 생성된 데이터셋과 DSPy의
MiPROv2알고리즘으로 프롬프트 최적화 진행 - MLFlow로 분류 정확도 트래킹
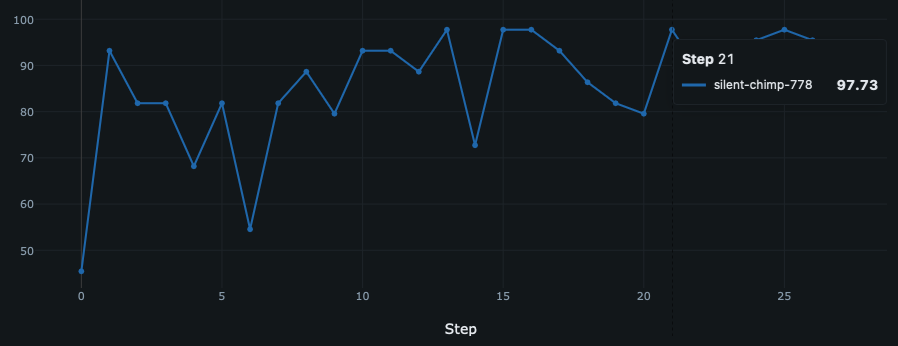
MLFlow로 트래킹한 프롬프트 엔지니어링 분류 정확도
이런 식으로 개발하니, 프롬프트가 잘 작동하는지를 수치화해서 확인할 수 있고, 실제 배포했을 때도 새로운 질문에도 꽤 높은 정확도로 노드가 작동하는 것을 확인하였습니다.
MCP toolbox for Databases로 에이전트 DB 연동 프로세스 간소화

출처: MCP Toolbox for Databases 공식 문서
MCP toolbox for Databases (이하 MtD)는 구글에서 개발한 (이름이 좀 많이 긴) 데이터베이스 MCP 서버 생성 툴입니다. 다양한 데이터베이스 (PostgreSQL 포함)를 지원해서 폭넓은 프로젝트에 적용이 가능합니다. MtD는 기존 코드를 작성해야 하는 데이터베이스 MCP서버 개발 프로세스를 최소한 단순화해서 boilerplate 코드 없이 아래와 같이 간단한 yaml파일 작성과 bash스크립트 한 줄이면 바로 MCP서버를 배포할 수 있게 해주는 유용한 툴입니다.
sources:
my-pg-source:
kind: postgres
host: ${DB_HOST}
port: ${DB_PORT}
database: postgres
user: ${USER_NAME}
password: ${PASSWORD}
tools:
search-hotels-by-name:
kind: postgres-sql
source: my-pg-source
description: Search for hotels based on name.
parameters:
- name: name
type: string
description: The name of the hotel.
statement: SELECT * FROM hotels WHERE name ILIKE '%' || $1 || '%';
search-hotels-by-location:
kind: postgres-sql
source: my-pg-source
description: Search for hotels based on location.
parameters:
- name: location
type: string
description: The location of the hotel.
statement: SELECT * FROM hotels WHERE location ILIKE '%' || $1 || '%';
YAML 파일을 작성한 뒤 서버 배포는 아래와 같이 간단하게 명령줄 한 줄로 배포가 가능합니다.
toolbox --tools-file "tools.yaml" --ui
INFO "Toolbox UI is up and running at: http://localhost:5000/ui"
배포가 완료된 후, 로그를 확인하여 MCP 서버에 배포되어 있는 주소로 접속하면, 서버에서 사용할 수 있는 툴 리스트를 UI를 통해 확인할 수 있습니다.
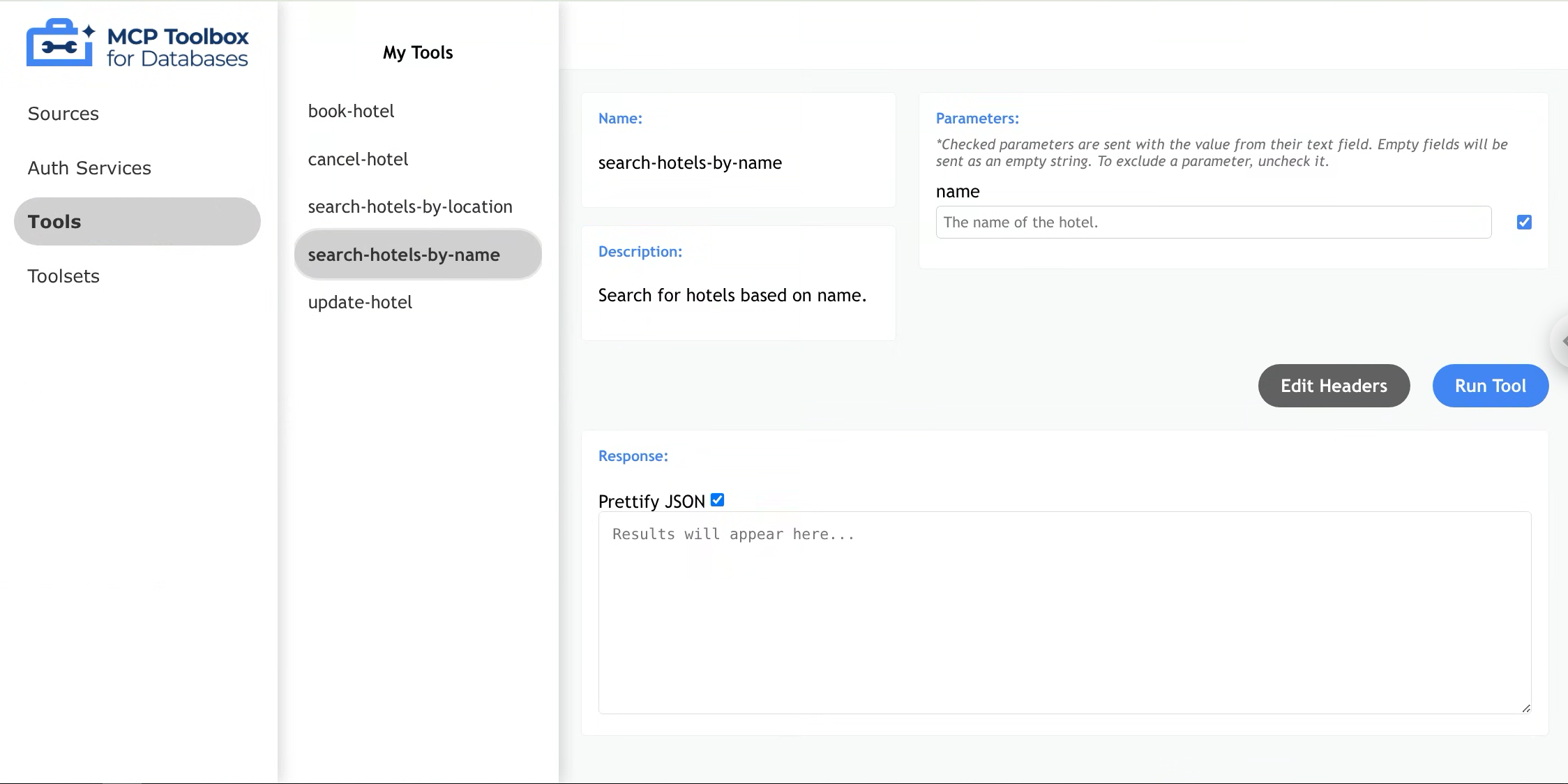
MCP toolbox for Databases UI
이 툴의 장점은 크게 두 가지입니다. 첫째, 데이터베이스 관련 MCP 서버 개발 시간을 비약적으로 단축합니다. 필요한 쿼리를 도구화한 YAML 파일과 한 줄의 Bash 스크립트만 준비하면, 바로 MCP 서버를 사용할 수 있는 간편함 덕분에 프로젝트에 적용하기에 매력적으로 다가왔습니다.
또한 에이전트가 질문이나 주제와 관련된 데이터를 불러오는 시간도 줄여줍니다. 보통 에이전트와 데이터베이스를 연동할 때는 text-to-SQL을 많이 사용합니다. 하지만 간단한 쿼리에도 RAG 적용, 쿼리 검증 및 재작성 과정을 거치면서 최종 답변까지의 레이턴시가 누적될 수 있습니다. MCP Toolbox for Databases는 자주 사용하는 쿼리를 도구화해두면 LLM 에이전트가 필요한 도구만 호출해 바로 관련 데이터를 데이터베이스에서 추출할 수 있으므로, 응답 시간을 유의미하게 줄일 수 있습니다.
Observability

Google Nano Banana를 사용한 이미지 생성
에이전트 개발/디버깅에서도, 다른 개발 작업과 마찬가지로 중간 상태를 확인하는 observability가 중요합니다. 특히 LangGraph로 에이전트를 개발할 때 에이전트가 고도화될수록 노드와 엣지가 많이 늘어나게 됩니다. 이때, 에이전트가 답변을 생성하는 과정을 손쉽게 확인할 방법이 없다면, 에이전트가 왜 특정 답변을 내놓았는지, 어떤 노드가 잘 동작하지 않는지를 파악하기 수월하지 않습니다.
또한, LLM Agent 개발/배포하면서 LLM 에이전트에 사용한 질문과 답변을 기록하는 observability 시스템을 갖추면, 추후에 모델 고도화에 사용할 수 있는 데이터가 축적됩니다.
LangChain이나 LangGraph를 사용해서 에이전트를 트레이싱할 때는 보통 LangSmith를 사용합니다. LangChain 개발 팀에서 만들어 연동도 편하고, 부수 기능을 많이 제공하지만, 첫 5,000개의 트레이싱 이후에는 비용이 추가되고, 데이터 저장도 14일 또는 400일 이후 삭제된다는 단점이 있습니다. 또한, 민감한 데이터를 다루는 에이전트라면 외부로 노출될 수 있는 단점 또한 존재합니다.
만약, 데이터를 오랫동안 유지를 해야 하거나, 데이터 보안이나 유출에 신경 써야 한다면, 오픈소스 LLM 로깅 플랫폼을 사용하는 것을 추천합니다. 저는 프로젝트할 때 Langfuse라는 툴을 자주 사용합니다. 초기 설정도 비교적 편하고, 다른 오픈소스 LLM Observability툴들에 비해 커뮤니티 규모가 커서, 디버깅하기 편리한 장점이 있습니다.

출처: Langfuse 공식 문서
마무리
이번 글에서는 DSPy로 분기 노드를 체계적으로 최적화하는 방법, MCP Toolbox for Databases로 DB 연동을 간소화하는 방법, 그리고 Langfuse를 중심으로 관측 가능성을 강화하는 방법을 다뤘습니다. 세 가지는 서로 분리된 체크리스트가 아니라, 빠르게 실험하고 학습하며 개선을 가속하는 하나의 루프를 이룹니다. 작은 개선을 한두 가지부터 적용해 보시고, 지표로 확인하면서 점진적으로 확장해 보시는 걸 추천합니다.
실제 적용하면서 생긴 인사이트나 질문이 있다면 댓글로 남겨 주세요. 다음 글에서는 더 다양한 유스케이스를 바탕으로 프롬프트/툴/관측 설계를 한 단계 확장하는 방법을 정리해 보겠습니다.
